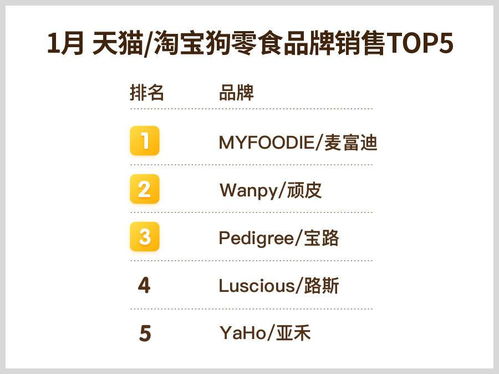
隨著消費升級和生活節奏的加快,烘焙產品正從傳統的糕點店、商超貨架,快速滲透到早餐、下午茶、線上新零售、便利店、輕食簡餐乃至旅游伴手禮等多元化的銷售場景中。這一趨勢不僅拓展了烘焙市場的邊界,也為以南僑食品為代表的預制烘焙解決方案供應商帶來了前所未有的發展機遇。
一、 銷售場景的裂變與拓展
過去,消費者購買面包、蛋糕等烘焙食品,主要依賴于街邊烘焙坊和大型商超的現場制售或預包裝區域。如今,消費場景已發生深刻變化:
- 便捷化場景興起:便利店、自動販賣機、寫字樓內的智能貨柜成為消費者獲取早餐面包、簡易點心的熱門渠道,強調即時性和便利性。
- 餐飲融合加深:西式簡餐店、咖啡廳、茶飲店普遍將烘焙產品作為重要搭配,提升客單價和消費體驗;許多中餐廳也開始引入特色烘焙點心,豐富菜品結構。
- 線上渠道蓬勃發展:本地生活平臺、生鮮電商、品牌自營小程序等,使得網紅蛋糕、半成品面團、冷凍烘焙品的即時配送成為常態,滿足了居家烘焙和即時享用的需求。
- 跨界與禮品化:烘焙產品與節日、IP、健康概念結合,作為伴手禮、企業福利、節慶禮品銷售,提升了其附加值和文化屬性。
場景的多元化,意味著對烘焙產品的需求也呈現出差異化:既要滿足便利店對長保質期、標準化產品的需求,也要迎合精品咖啡館對高品質、差異化口味的需求,同時還需適應線上渠道對冷鏈配送、家庭復熱便捷性的要求。這對上游生產企業的研發、生產和供應鏈靈活性提出了更高挑戰。
二、 預制烘焙解決方案供應商的核心機遇
面對下游復雜多變的需求,單體烘焙店或餐飲企業自建完整生產線往往面臨成本高、研發周期長、品質不穩定等難題。這正是以南僑食品為代表的專業預制烘焙商的優勢所在和機遇所在。
- 規模化與標準化優勢:預制烘焙商擁有大型現代化生產基地,能夠實現原料的統一采購、生產流程的精密控制,確保產品口味、品質和安全的穩定性,完美匹配便利店、連鎖餐飲等對標準化要求極高的渠道。
- 研發創新驅動力:企業可以投入大量資源進行市場調研和產品研發,快速響應市場趨勢(如低糖、全麥、植物基、地方風味融合等),開發出適應不同場景的冷凍面團、預烤產品、餡料等,為下游客戶提供“菜單式”的解決方案,幫助其降低研發成本并快速上新。
- 供應鏈與成本效率:通過集中生產、集約化物流(特別是冷凍冷鏈),預制烘焙商能有效降低下游客戶的整體運營成本,解決其倉儲空間有限、現場加工人力成本攀升等問題,尤其助力中小型烘焙店和餐飲門店提升競爭力。
- 賦能下游品牌化:預制烘焙商作為“幕后英雄”,使下游客戶能夠更專注于前端品牌運營、門店體驗和市場營銷,實現輕資產快速擴張。例如,許多新興的網紅烘焙品牌和連鎖茶飲品牌,其爆款產品背后都有專業預制供應鏈的支撐。
三、 挑戰與未來展望
盡管機遇廣闊,預制烘焙商也面臨挑戰:消費者對“新鮮現制”的偏好依然存在,需要持續教育市場,提升對高品質預制產品(如冷凍面團經烘烤后口感媲美現制)的認知;市場競爭加劇,需持續加強技術創新和差異化服務;食品安全與冷鏈物流的管控要求極高。
烘焙產品銷售場景的多元化趨勢仍將持續深化。以南僑食品為例的領先企業,若能緊抓市場需求,強化研發能力,優化柔性供應鏈,并與下游客戶建立更緊密的合作共贏關系,將不僅能分享行業增長的紅利,更能推動整個烘焙產業向更加專業化、標準化和高效化的方向升級。預制烘焙的“中央廚房”角色,正日益成為支撐中國烘焙市場繁榮發展的隱形基石。